Datové struktury 1 - NTIN066 - ZS 2014/2015
4. úkol - výsledky
Informace o procesorech.
Příklady naměřených grafů:
Autor: Michal Koucky
Pocitac: genericky kancelarsky desktop
CPU: Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz
RAM: 16GB
Jazyk: C++
Nastavení kompilátoru: g++ -ansi -Wall -pedantic -lm -O3
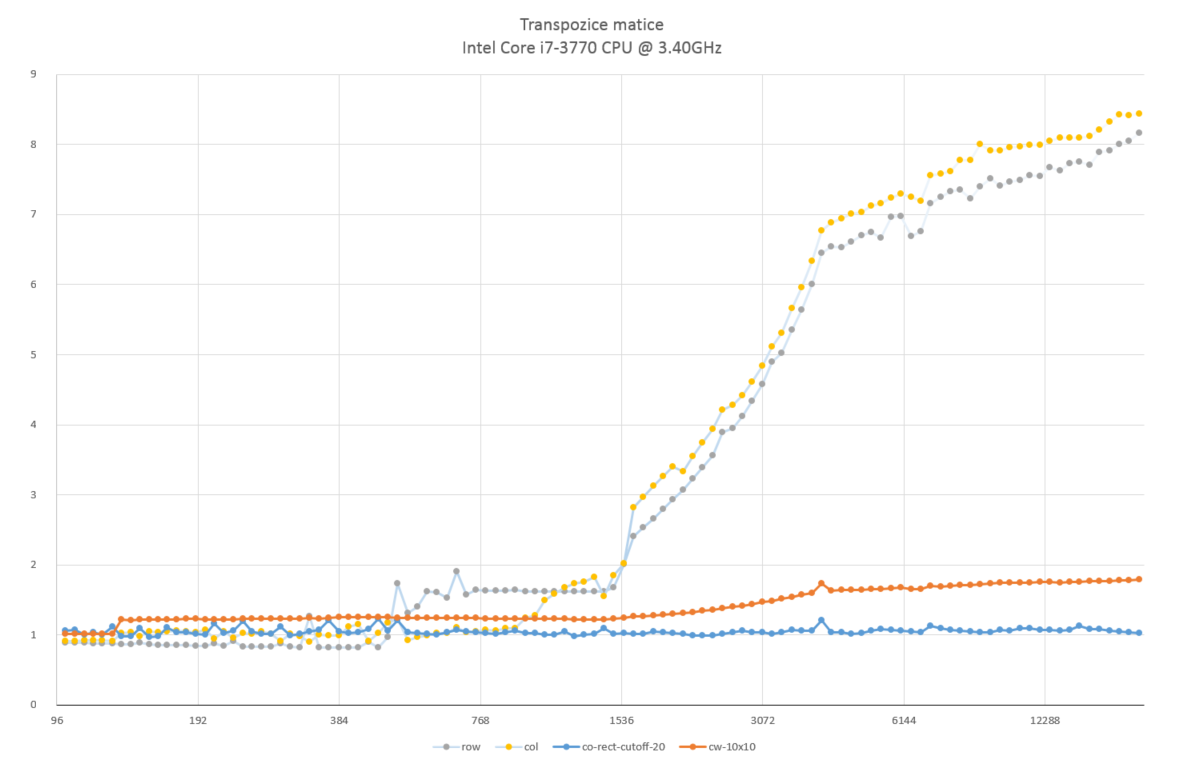
row - triviální transpozice po řádcích
col - triviální transpozice po sloupcích
co-rect-cutoff-20 - "cache-oblivious" algoritmus s ukončením rekurze na maticích, které mají součet dimenzí menších než 20.
cw-10x10 - "cache-aware" algoritmus s transpozicí po podmaticích dimenze 10x10.
Autor: Michal Koucky
Pocitac: genericky kancelarsky desktop
CPU: Intel(R) Core(TM)2 Quad CPU Q6600 @ 2.40GHz
RAM: 2GB
Jazyk: C++
Nastavení kompilátoru: g++ -ansi -Wall -pedantic -lm -O3
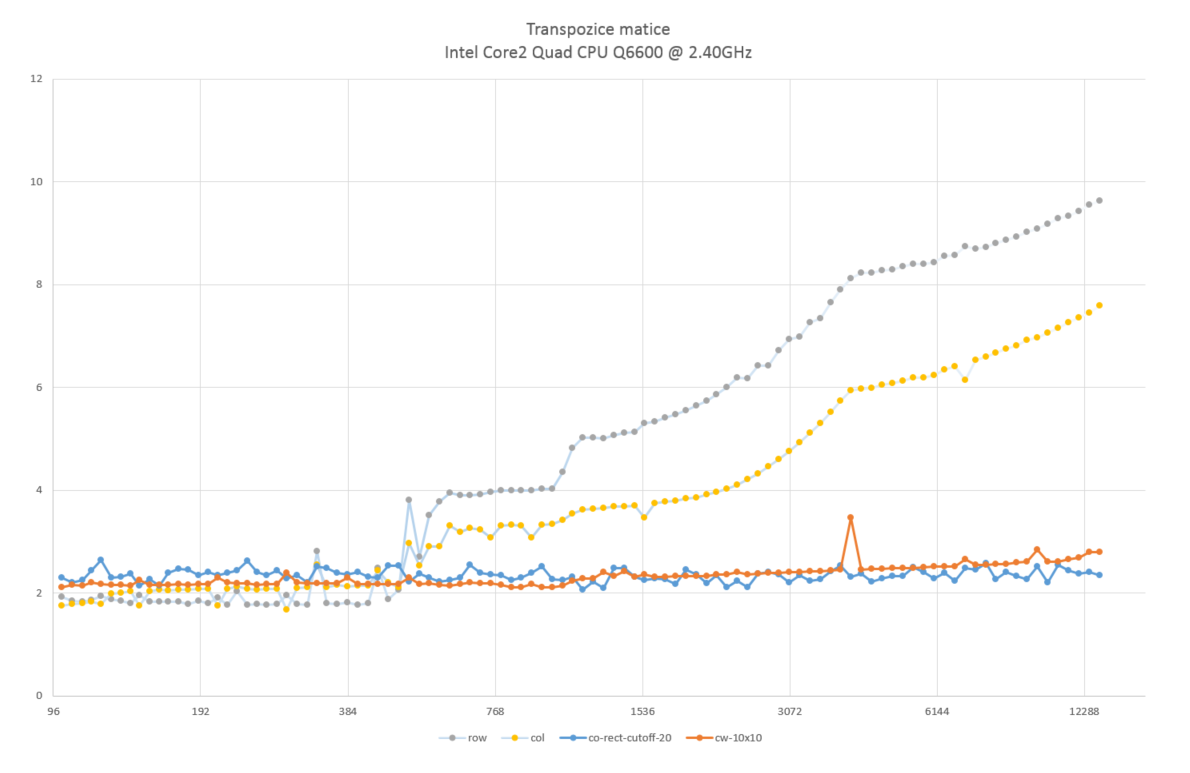
row - triviální transpozice po řádcích
col - triviální transpozice po sloupcích
co-rect-cutoff-20 - "cache-oblivious" algoritmus s ukončením rekurze na maticích, které mají součet dimenzí menších než 20.
cw-10x10 - "cache-aware" algoritmus s transpozicí po podmaticích dimenze 10x10.
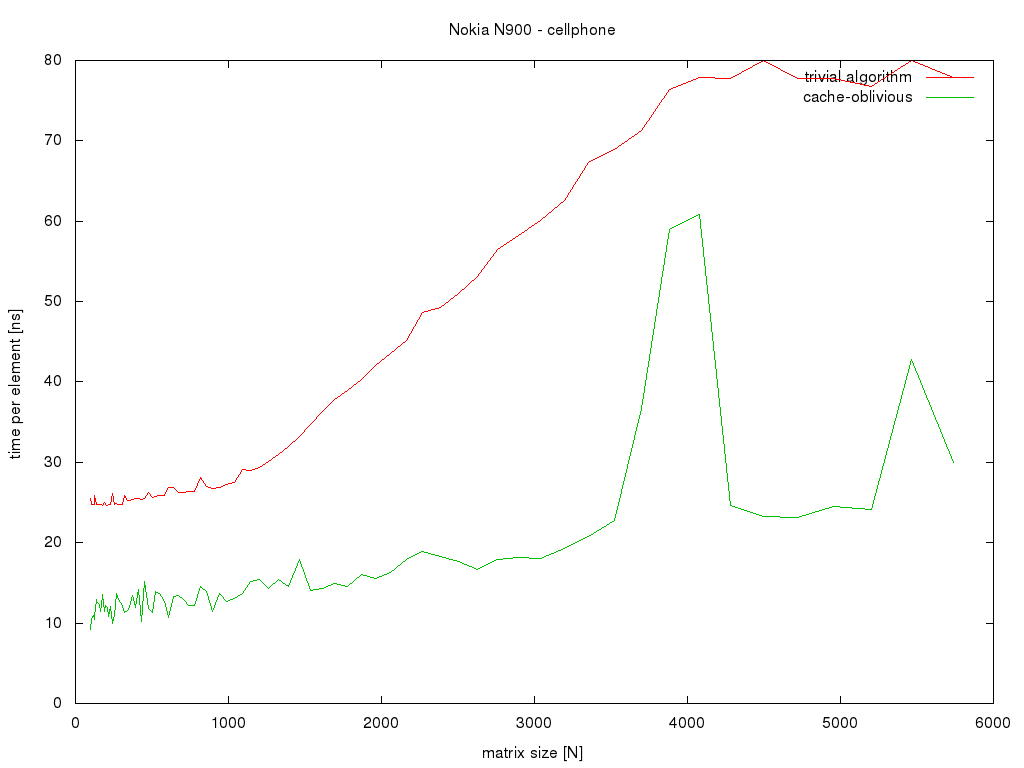
Autor: Pali
Pocitac: mobilny telefon Nokia N900
CPU: TI OMAP 3430 SoC - ARMv7-A Cortex-A8 600 MHz
RAM: 256 MB (program pouzival jen 96 MB)
Jazyk: C
Nastavení kompilátoru: arm-none-linux-gnueabi-gcc -std=gnu99 -W -Wall -march=armv7-a -mcpu=cortex-a8 -
mtune=cortex-a8 -mfpu=neon -mfloat-abi=softfp -mthumb -mno-thumb-interwork -ftree-vectorize -fomit-frame-
pointer -Ofast
Poznamka: Pri maticiach okolo velkosti 4000x4000 to aj pri opakovanych meraniach trvalo pre cache-
oblivious algoritmus asi 3-nasobne dlhsie ako pre mensie a vacsie matice. Vyrazny skok v grafe pre tieto
velkosti som nameral vzdy. Graf vychadzal aj pri opakovanych meraniach skoro uplne rovnaky a neni vidno
co to sposobuje.
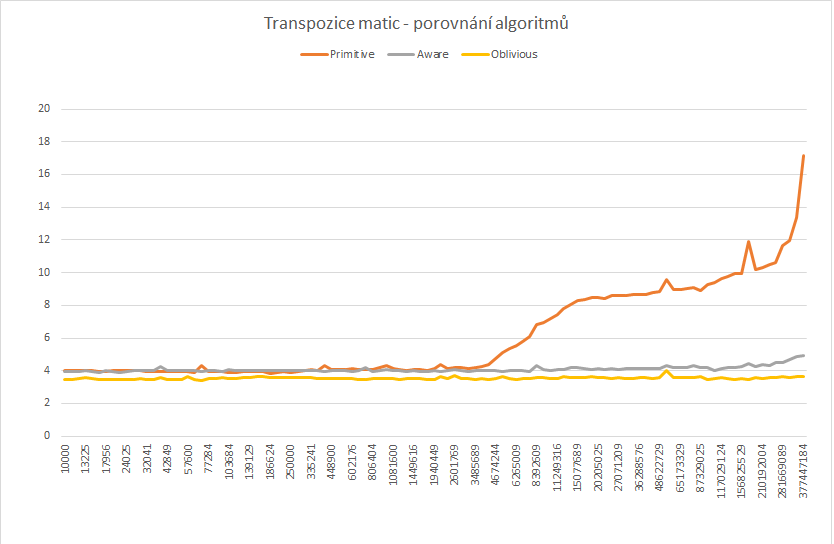
Autor: Karel
Pocitac: notebook Lenovo T410s
CPU: Intel(R) Core(TM) i5 CPU M 540 @ 2.53 GHz
RAM: 4GB (využito 1,7 GB)
Jazyk: C++
Nastavení kompilátoru: /GL /O2 (kompiluje Visual Studio - MSVC++2010, x64)
Poznamka: Cache-Oblivius algoritmus jsem implementoval tak, že jsem ho při dostatečně malé matici "zařízl"
a zbytek jsem transponoval primitivním algoritmem. Jako vhodná hranice na mém počítači se ukázal rozměr 64x64.
Pokud je matice větší, tak se rozdělí na čtyři a rekurzivně transponuje, pokud je menší, tak se transponuje
primitivně pomocí dvou for cyklů.
Pro Cache-Aware algoritmus jsem velikost bloku nastavil na 8, tato hodnota vykazovala nejlepší performance.
Zajímavé je, že je to výrazně menší než hodnota u Cache-Oblivious řešení. Pro matice menší než 64 však
Cache-Oblivious řešení dle mého měření již není vhodné, protože je složitější a vytěžuje procesor více než
triviální algoritmus.
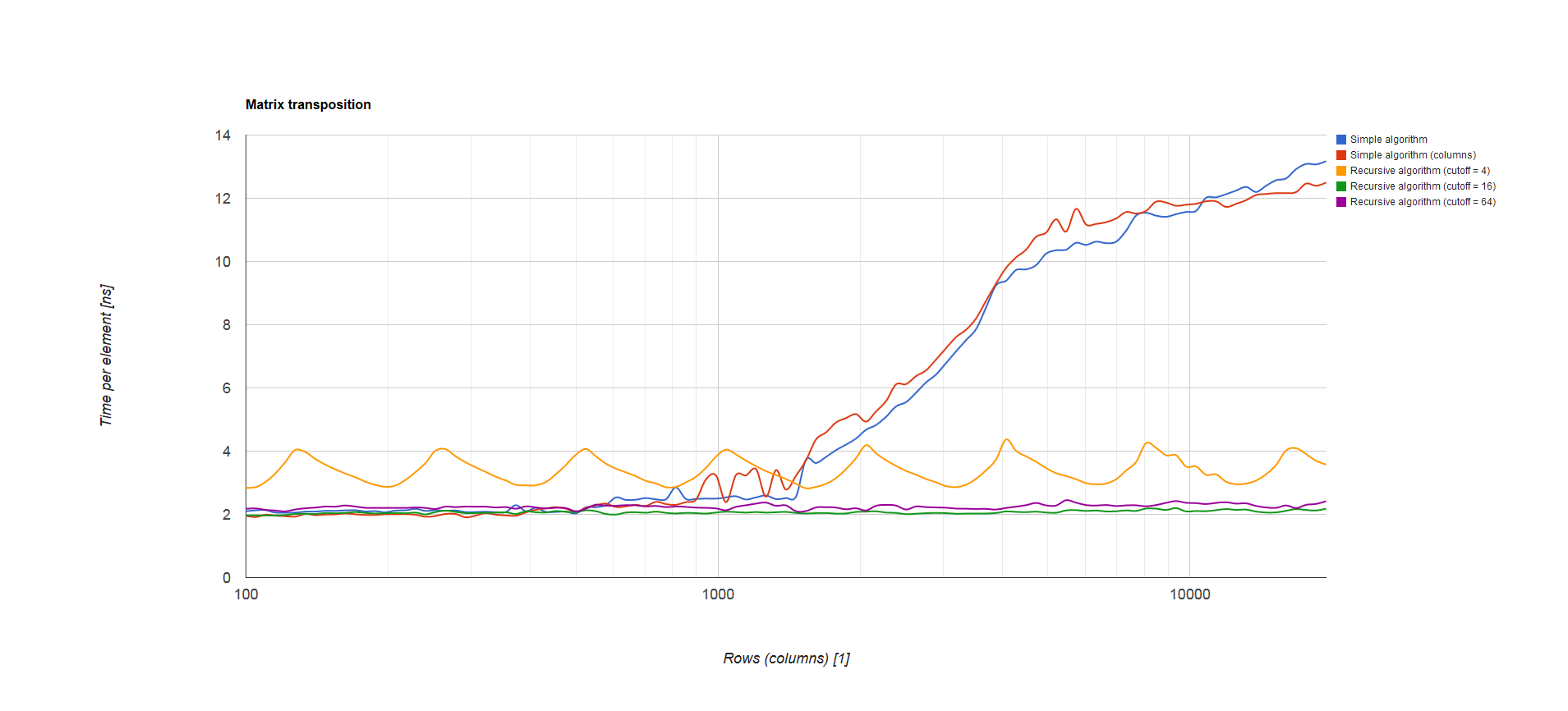
Autor: Vít Šefl
Počítač: 3.5 roku starý herní notebook
CPU: Intel(R) Core(TM) i7-2630QM CPU @ 2.00 GHz
RAM: 8 GB
Jazyk: C++
Nastavení kompilátoru: g++ --std=c++11 -O3 -Wall -Wextra
Autor: Fifinka
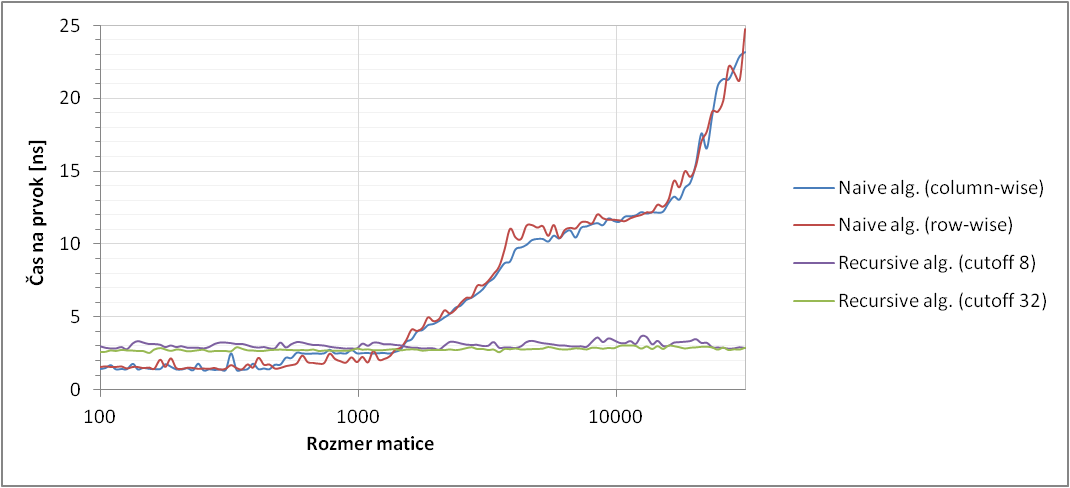
Pocitac: notebook Dell XPS L502x
CPU: Intel(R) Core(TM) i5-2410M CPU @ 2.30GHz
RAM: 4 GB
Jazyk: C++
Nastavení kompilátoru: /GL /O2 (Visual C++)
Souhlasim se zverejnenim vysledku na webu: ano
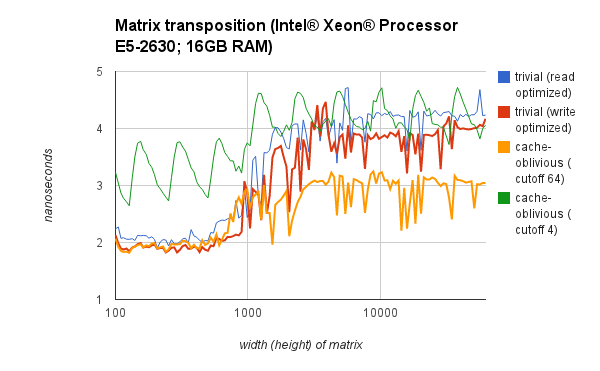
Autor: David Honzátko
Pocitac: knight.ms.mff.cuni.cz (NUMA 2xCPU)
CPU: Intel® Xeon® Processor E5-2630
RAM: 16GB
Jazyk: C++
Nastavení kompilátoru: icpc -std=c++0x -O2 -Wall -march=native
Pozn: Protože vyšly grafy poměrně zajímavé, ověřil jsem chování na u-pl12, tam vyšly podobné hodnoty jako ostatním.
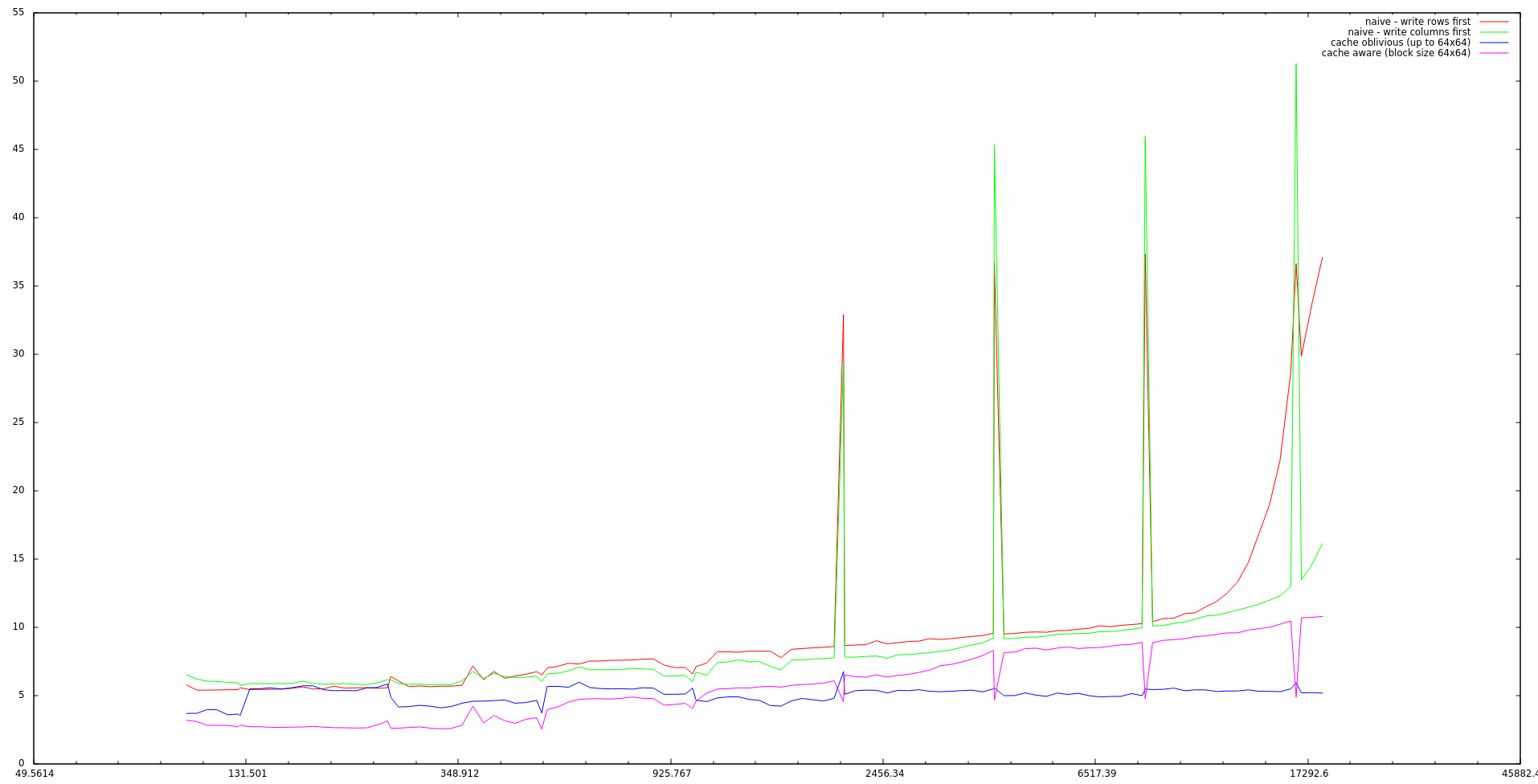
Autor: Floop
Pocitac: 7 let stary laptop
CPU: Intel(R) Core(TM)2 Duo CPU T8300 @ 2.40GHz
RAM: 4GB
Jazyk: C++11
Nastavení kompilátoru: g++ -std=c++11 -march=native -O3 -fomit-frame-pointer -funroll-all-loops -Wall -pedantic
Poznámka: Časy jsem měřil přímo v programu a pouze pro samotný proces transpozice, aby nedocházelo k odchylkám způsobeným
alokacemi apod. Matice jsem předvyplnil náhodnými čísly, aby operační systém nemohl odkládat alokaci paměti až na první
přístup a neprojevilo se to na výsledcích. Navíc oproti zadání jsem do grafu přidal časy pro matice se stranou 2^k.
Při těchto velikostech docházelo u triviálních algoritmů k obrovským špičkám. Cache-oblivous algoritmus byl vůči tomuto
jevu imunní a cache-aware algoritmus dokonce zrychloval. Také se dá všimnout, že se u triviálního algoritmu vyplatí číst
po řádcích a zapisovat po sloupcích.
Autor: Jiri
Pocitac: iPhone7,2
CPU: Apple A8 @ 1.4GHz
RAM: 1GB
Jazyk: C
Prekladac: Apple LLVM version 6.0 (clang-600.0.56) (based on LLVM 3.5svn)
Nastaveni: -std=gnu99 -arch arm64 -O3
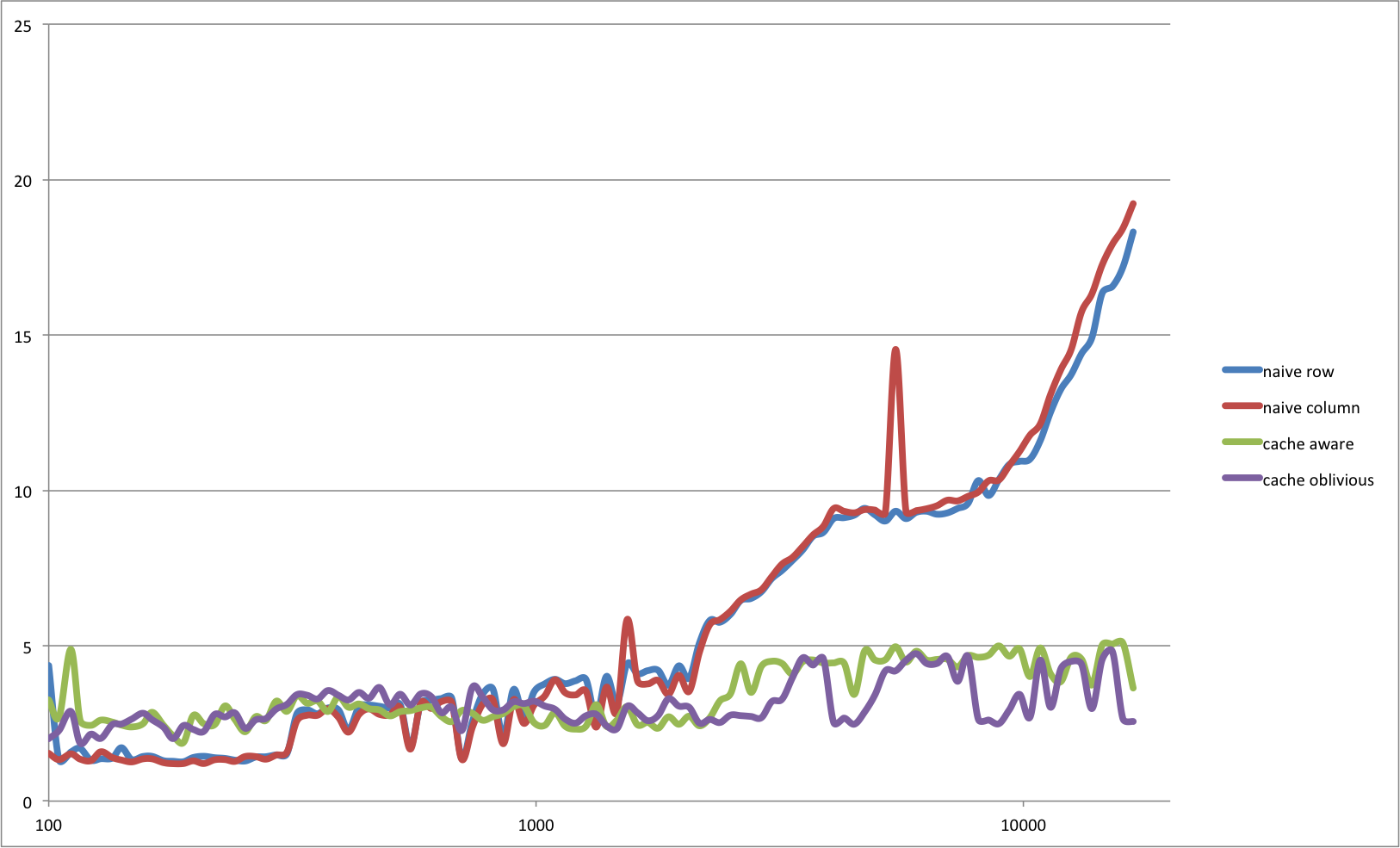
naive_row - 2xfor po radcich
naive_column - 2xfor po sloupcich
cache_aware - 4xfor po radcich a blocich pevne velikosti (32x32)
cache_oblivious - rekurzivni algoritmus, ktery bloky ctvrti (az do velikosti 32x32, pak naive_row)
Autor: Jiri
Pocitac: iPad3,3
CPU: Apple A5X @ 1.0GHz
RAM: 1GB
Jazyk: C
Prekladac: Apple LLVM version 6.0 (clang-600.0.56) (based on LLVM 3.5svn)
Nastaveni: -std=gnu99 -arch armv7 -O3
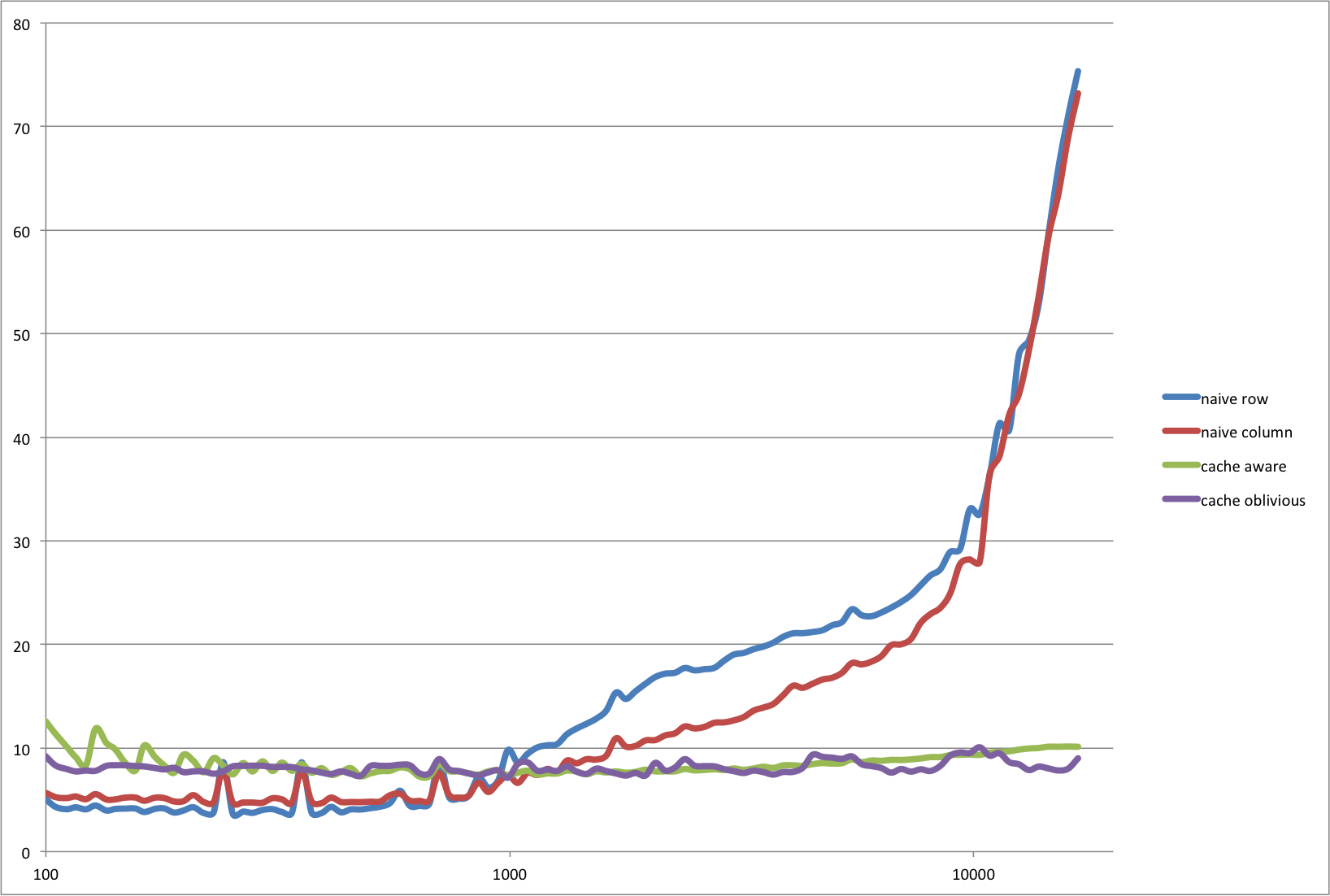
naive_row - 2xfor po radcich
naive_column - 2xfor po sloupcich
cache_aware - 4xfor po radcich a blocich pevne velikosti (32x32)
cache_oblivious - rekurzivni algoritmus, ktery bloky ctvrti (az do velikosti 32x32, pak naive_row)
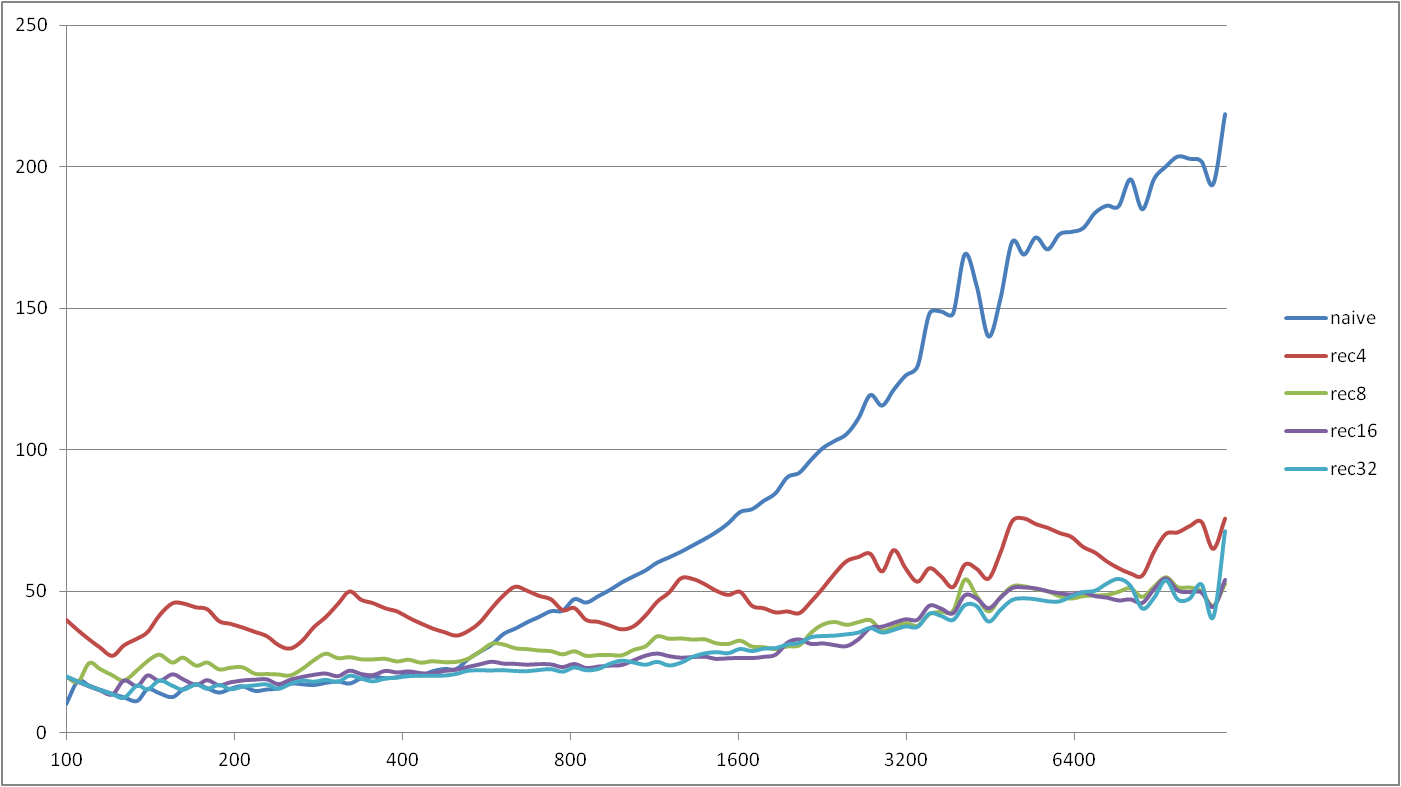
Autor: Jiří Švancara
Počítač: Raspberry Pi Model B Revision 2.0
CPU: Broadcom BCM2835
RAM: 512 MB
Jazyk: C++
Nastavení kompilátoru: g++ -Wall -Wextra -pedantic -O3
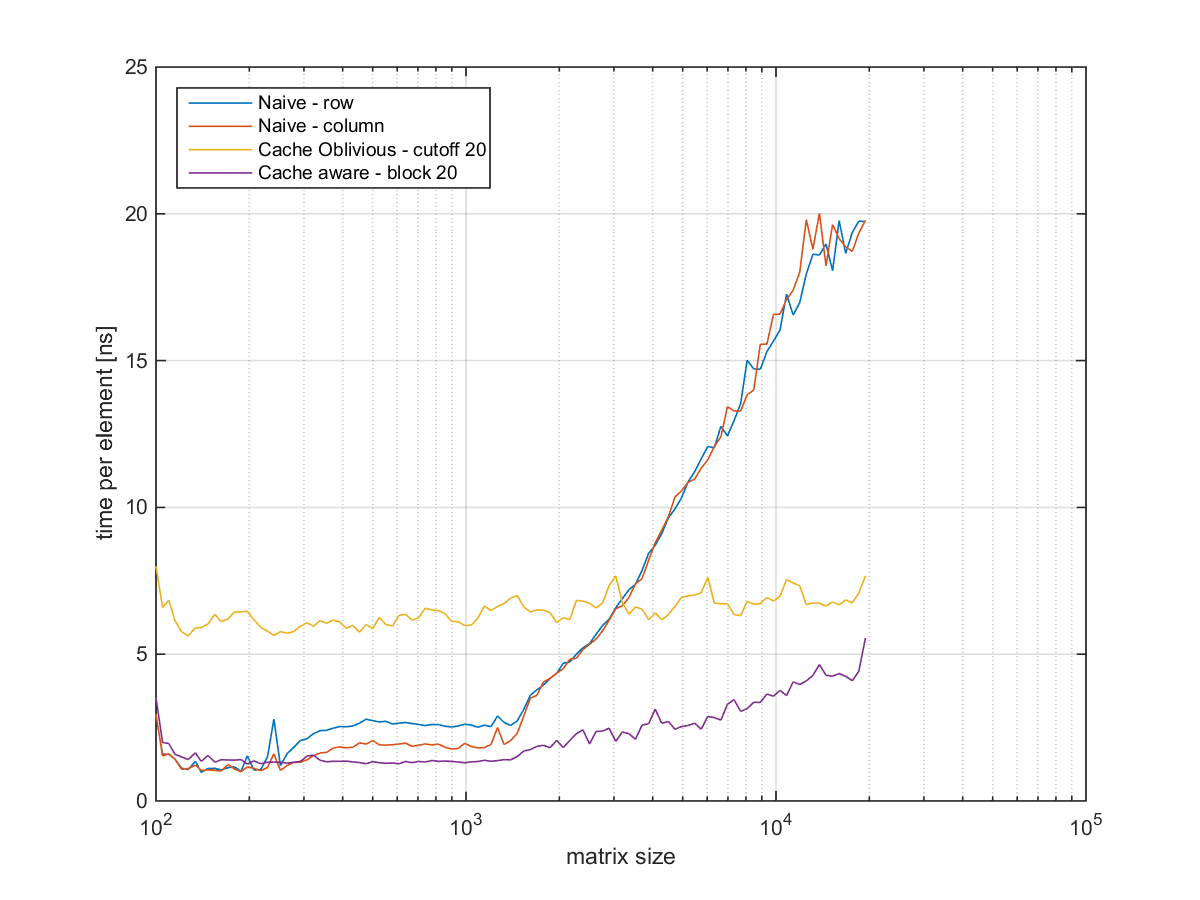
Autor: Princess Luna
Pocitac: Asus N750 JV
CPU: Intel(R) Core(TM) i7-4700HQ CPU @ 2.40GHz
RAM: 8GB
Jazyk: C# (v prostredi Windows)
Nastavení kompilátoru: Release conf. s optimalizaciami
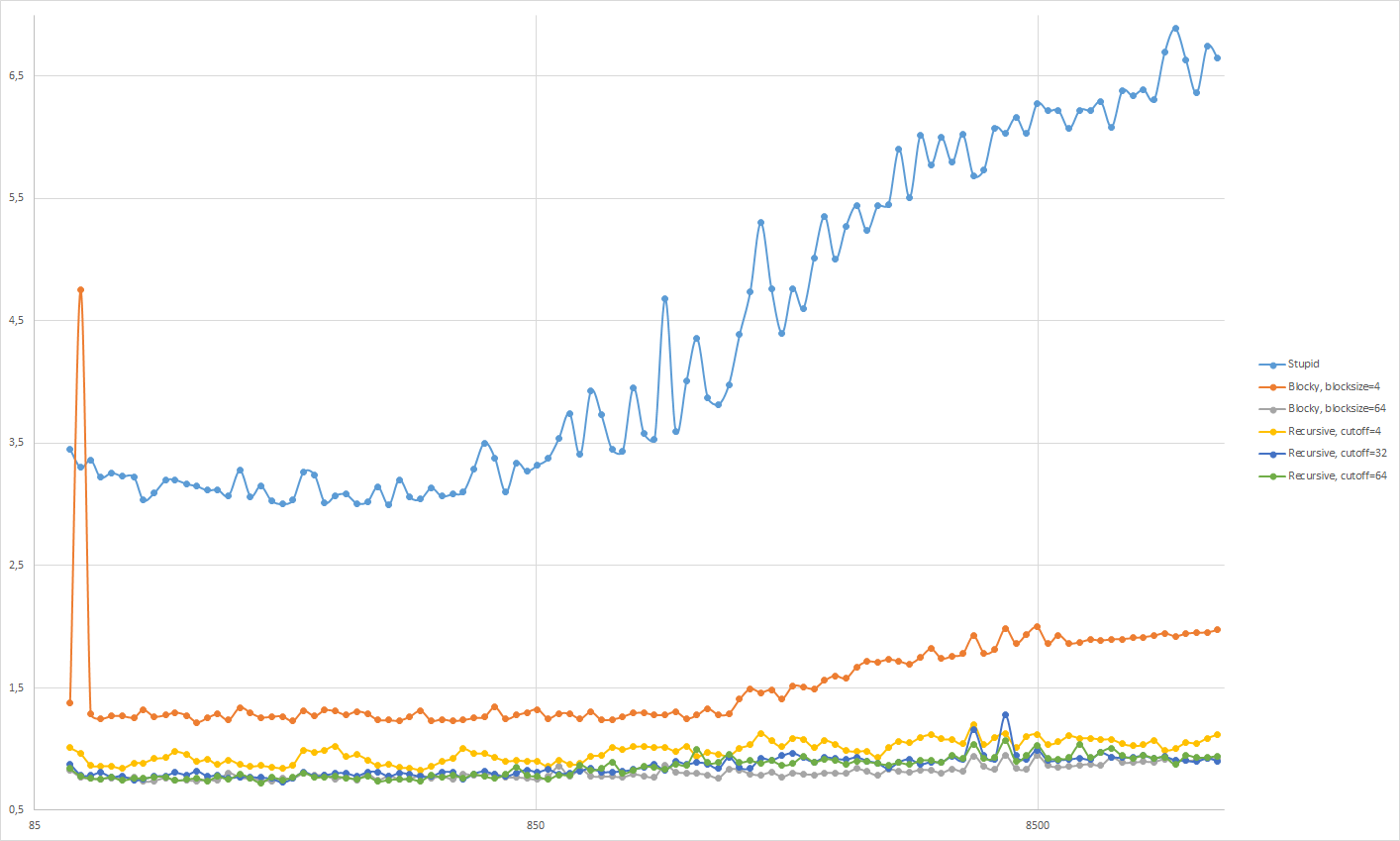
Stupid - obycajne riesenie s dvomi for-cyklami, brane po riadkoch do noveho miesta
Blocky, blocksize=X - riesenie styrmi for-mi, transpozicia po blokoch do noveho miesta. Velkost bloku X.
Recursive, cutoff=X - rekurzivne riesenie do noveho miesta. Ukoncenie rekurzie pri podmatici s "hranou" dlzky X alebo mensou.
Autor: ag
Počítač: Kobo Aura (čtečka elektronických knih)
CPU: Freescale i.MX507 - ARM Cortex-A8 @ 1GHz
RAM: 256MB
Jazyk: C
Nastavení kompilátoru: arm-linux-gnueabihf-gcc -march=armv7-a -mtune=cortex-a8 -Ofast -funroll-loops -fomit-frame-pointer -lm
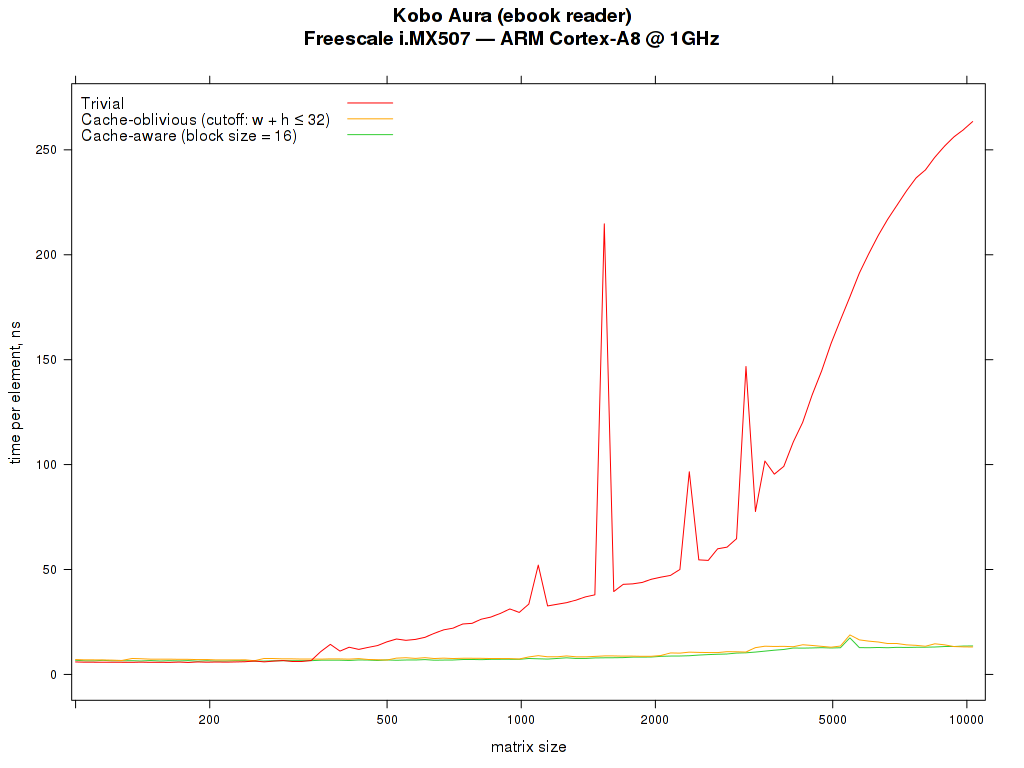
Autor: dsStudent
Pocitac: vlastni stolni pocitac
CPU: AMD A6 X4 3650 @ 2.60GHz
RAM: 8GB
Jazyk: C++
Nastavení kompilátoru: g++ -std=c++11 -O3
Poznámka: Matice jsem zkousel az do radu 44685. Vysledny cas pro kazdy rad R jsem spocital jako prumer z N transpozic matic radu R,
kde N = MIN(1000,(3GB/"velikostMaticeRaduR")). U cache-oblivious jsem prepinal na klasicky alg. pri jednom rozmeru matice < 20.
U klasickeho algoritmu jsem pri prehozeni cyklu nezaznamenal zadny vyrazny rozdil.
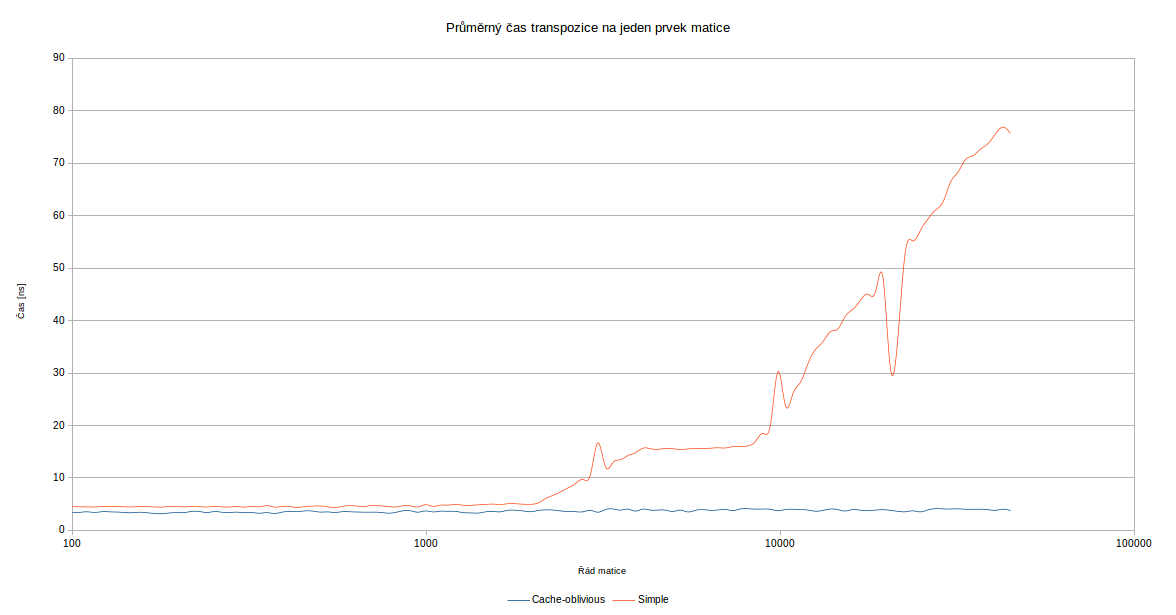
Autor: Folwar
Pocitac: Muj prvni pocitac
CPU: AMD Athlon XP 2500+ @ 1.8GHz
RAM: 1GB (pouzito 800MB)
Jazyk: C
Nastavení kompilátoru: gcc -Wall -O3 -std=gnu11 -march=native -lm
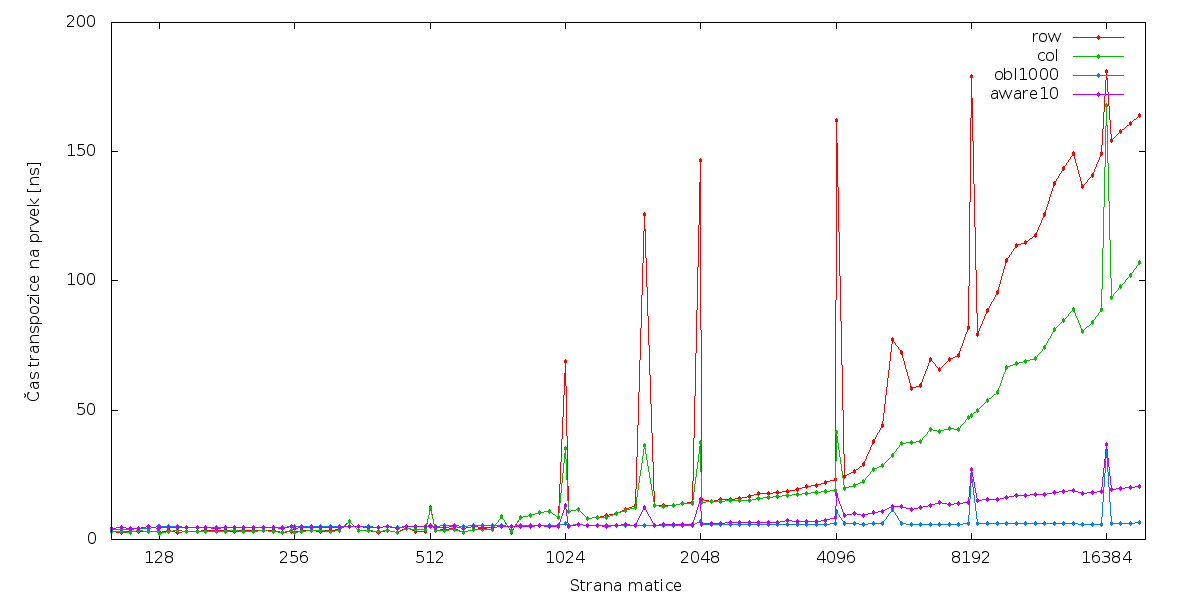
awareX oznacuje algoritmus, ktery transponuje po blocich velikosti X x X.
oblX oznacuje cache-oblivious algoritmus, ktery zarezava, je-li soucin dimenzi matice mensi nez X.
Autor: Jakub Cerny
Pocitac: MacBook Pro (15-inch, Mid 2012)
CPU: Intel(R) Core(TM) i7 (I7-3720QM)
RAM: 8GB
Jazyk: Java
Detailnější měření
Autor: Michal Koucky
Pocitac: genericky kancelarsky desktop
CPU: AMD Phenom(tm) II X6 1055T (2.8GHz)
RAM: 8GB
Jazyk: C++
Nastavení kompilátoru: g++ -ansi -Wall -pedantic -lm -O3
Poznámka: Změřeno téz v mocninách dvojky a násobcích 2048, které jsou vetší než 12000, a jejich okolí.
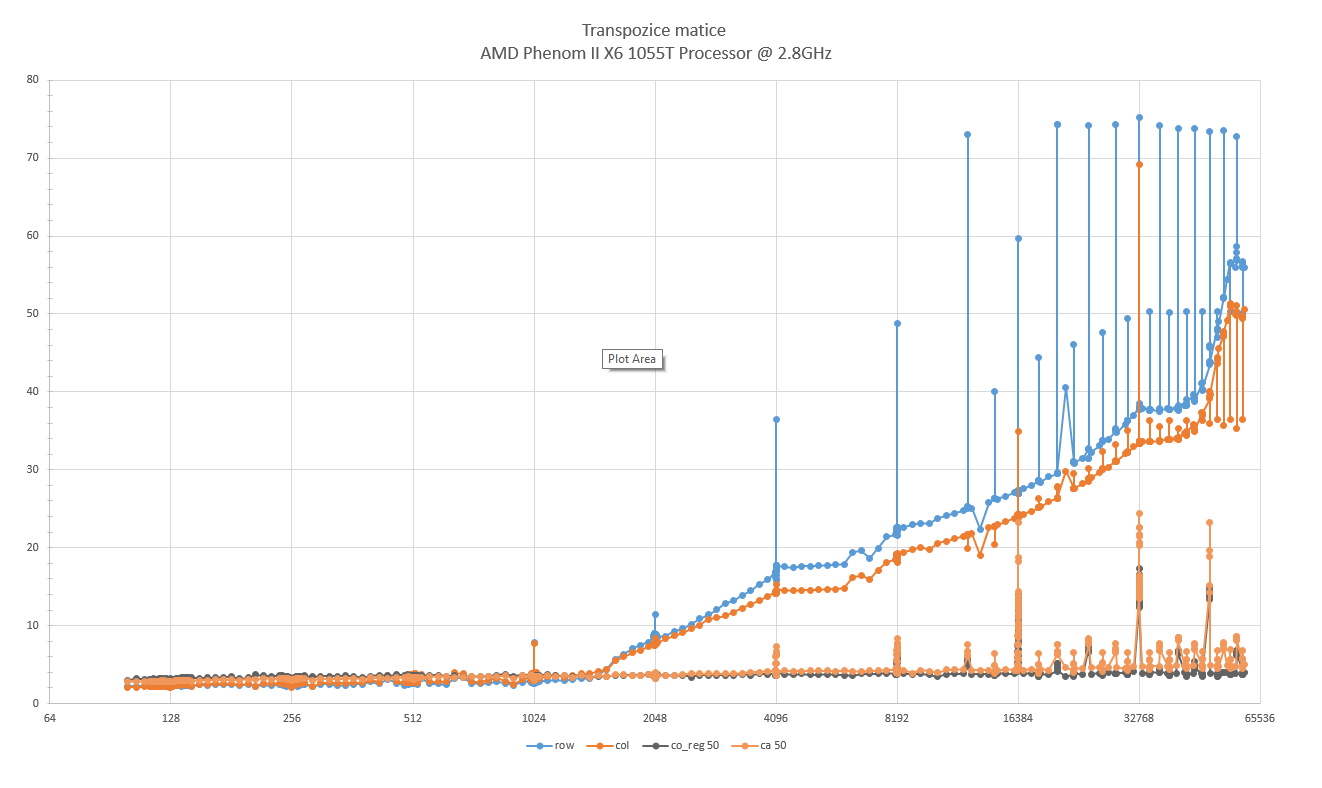
row - triviální transpozice po řádcích
col - triviální transpozice po sloupcích
co_reg 50 - "cache-oblivious" algoritmus s ukončením rekurze na maticích, které mají součet dimenzí menších než 50.
ca 50 - "cache-aware" algoritmus s transpozicí po podmaticích dimenze 50x50.
Autor: Michal Koucky
Pocitac: genericky kancelarsky desktop
CPU: Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz
RAM: 16GB
Jazyk: C++
Nastavení kompilátoru: g++ -ansi -Wall -pedantic -lm -O3
Poznámka: Změřeno téz v okolí bodů, které jsou mocninou dvojky.
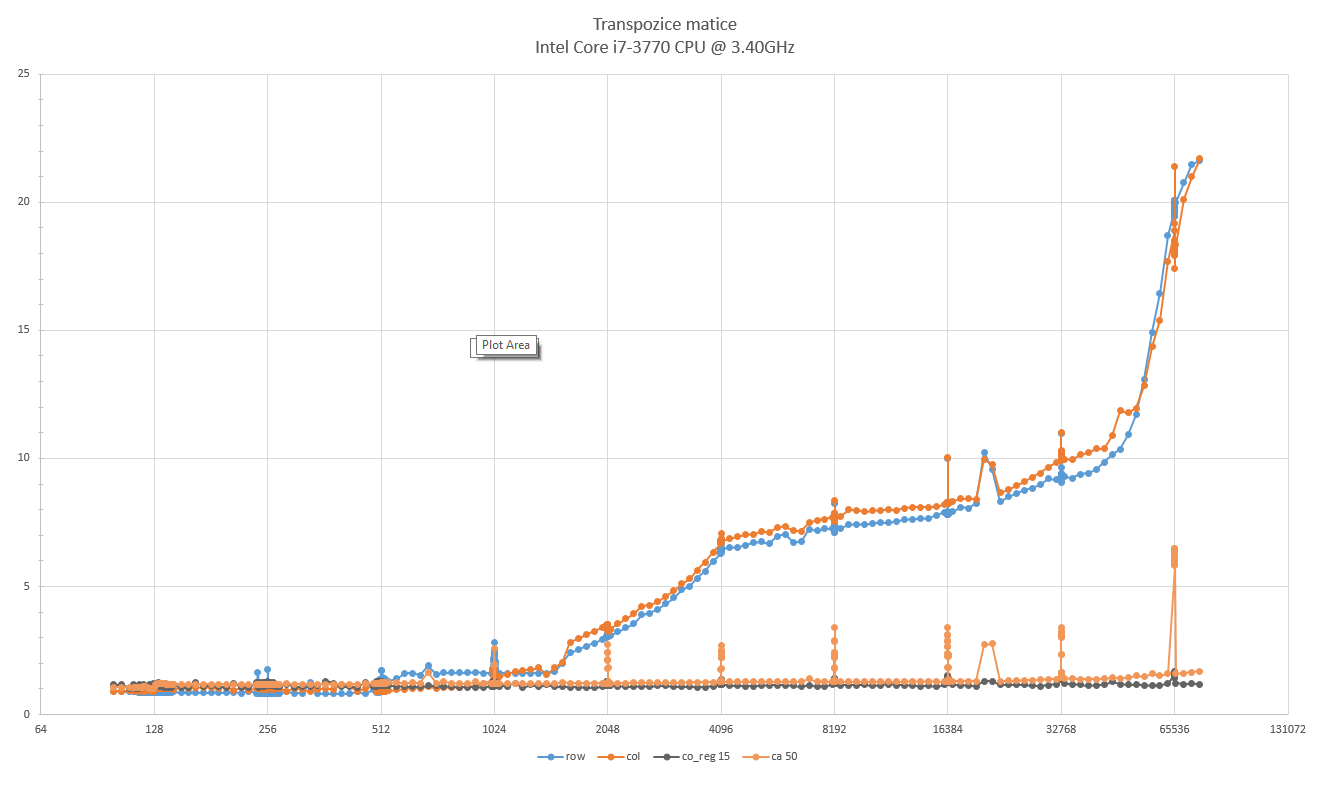
row - triviální transpozice po řádcích
col - triviální transpozice po sloupcích
co_reg 15 - "cache-oblivious" algoritmus s ukončením rekurze na maticích, které mají součet dimenzí menších než 15.
ca 50 - "cache-aware" algoritmus s transpozicí po podmaticích dimenze 50x50.
Autor: Michal Koucky
Pocitac: genericky kancelarsky desktop
CPU: Intel(R) Core(TM)2 Quad CPU Q6600 @ 2.40GHz
RAM: 2GB
Jazyk: C++
Nastavení kompilátoru: g++ -ansi -Wall -pedantic -lm -O3
Poznámka: Změřeno téz v násobcích 512, které jsou vetší než 2000, a jejich okolí.
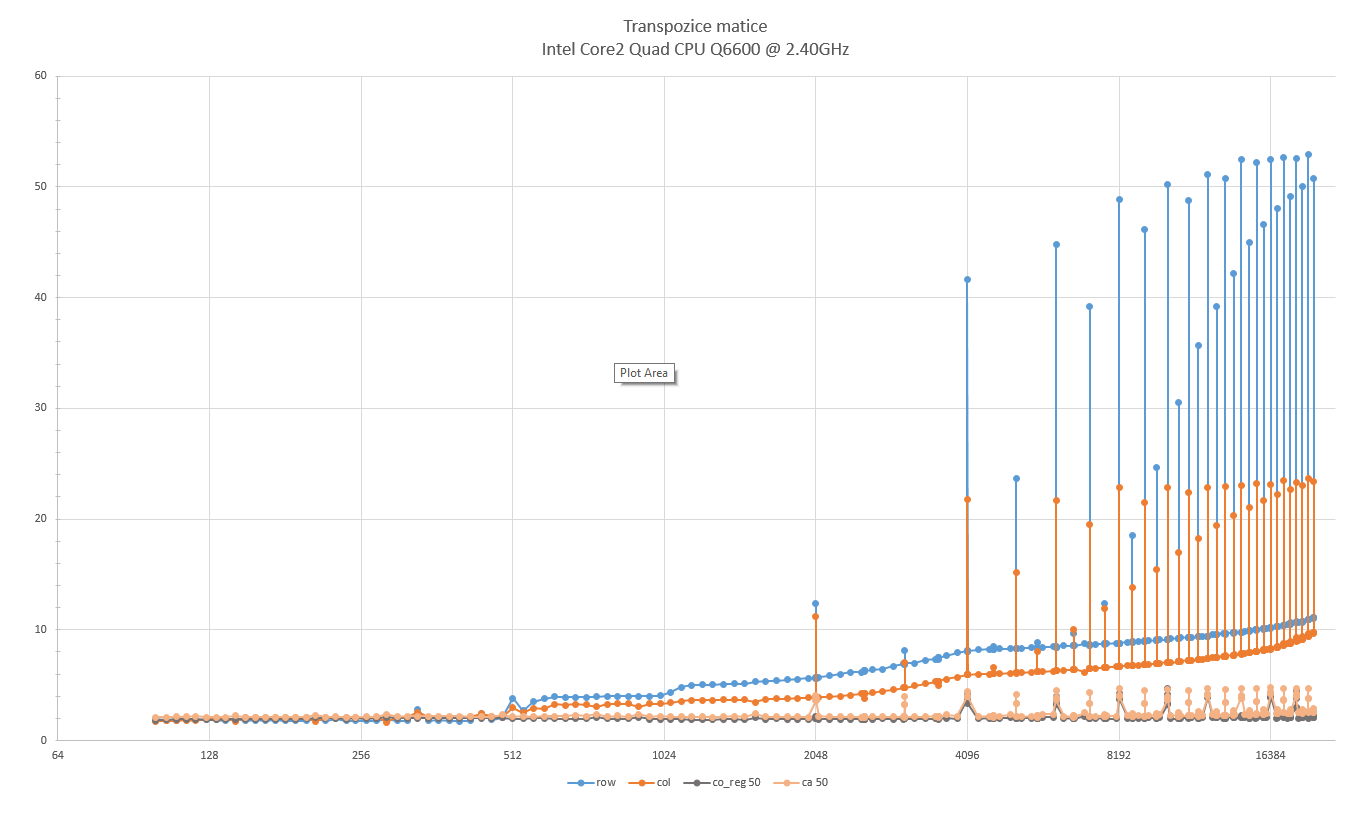
row - triviální transpozice po řádcích
col - triviální transpozice po sloupcích
co_reg 50 - "cache-oblivious" algoritmus s ukončením rekurze na maticích, které mají součet dimenzí menších než 50.
ca 50 - "cache-aware" algoritmus s transpozicí po podmaticích dimenze 50x50.